Clustering Analysis
Clustering is an unsupervised learning. It can divide the objects of analysis into different groups based on their features, in other words dividing the data in the dataset into clusters with similar characteristics. The goal lets data within a category to be more similar than data between different categories. Clustering analysis is different from classification, which is a supervised learning method that requires learning a classification from a training dataset. Clustering analysis is widely used in the real world, it can be used in computer image recognition, medical image analysis, market research, commodity classification, etc.
Partitioning Clustering VS. Hierarchical Clustering
Clustering analysis has two types, which are Partitioning clustering and hierarchical clustering. Partitioning clustering is not hierarchical, it has not explicit structure between data to show that they are related to each other. K-Means and K-Medoids are the most common useful partitioning algorithms. Hierarchical clustering shows a hierarchical tree structure where each node represents a cluster. This method gradually merged data (Agglomerative Clustering) or divided (Divisive Clustering) until all the data was clustered together. It does not require the number of clusters (K values) to be specified in advance. Single-linkage, Complete-linkage, and Connectivity-based clustering are the most common algorithms of Hierarchical clustering. The time complexity of partitioning clustering is relatively low compared to the hierarchical distance, especially in the case of large data volume, because hierarchical clustering needs to consider the distance or similarity between the data for each step.
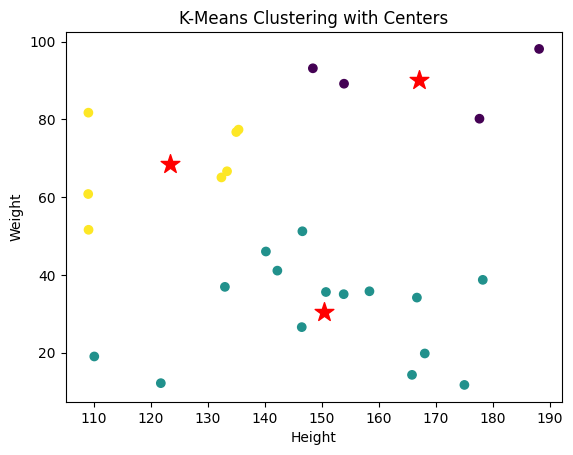
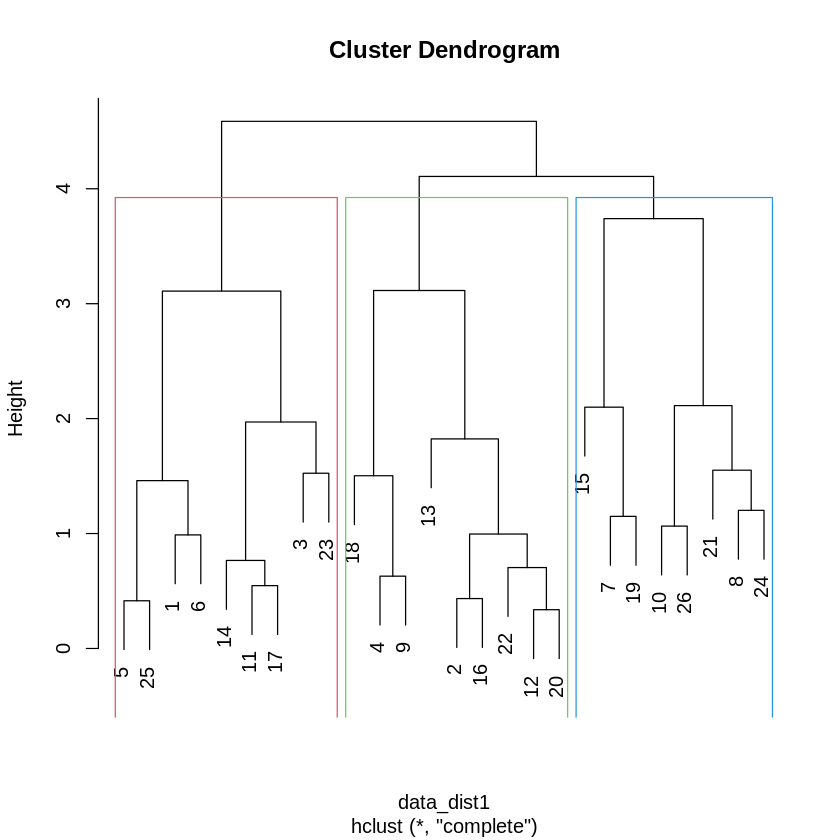
The plots above show the difference between the two categories of clustering. The Euclidean distance is used here, which is calculated straight-line distance between two points. The advantage of the Euclidean method is that is relatively simple to implement and intuitive. If a dataset is a low-dimensional dataset, the effect of using it is perfect. The dataset used in these two plots is low-dimensional(dataset).
$$\text{Euclidean Distance} = d(x,y) = \sqrt{\sum_{i=1}^{n} (x_{i}-y_{i})^2} $$
The most obvious difference between these two plots, as mentioned above, is that they show different structures. Partitioning clustering does not have a clear structure, and it can only be distinguished clusters by color and space. The plot of hierarchical clustering can show the division of clusters by tree structure. Using the K = 3 to display clusters, the partitioning and hierarchical plots have different amounts of data in each cluster. When using clustering analysis, may selecting different categories of clustering meets needs. For example, the partitioning method is a good choice when analyzing large-scale datasets, it is often more efficient and faster to perform. The hierarchical method is an option when exploring the structure of data clustering. It is suitable for working with small or medium-scale datasets, but it is expensive to work with large-scale datasets.
Clustering Plan
Finding the relationship between the shooting quality efficiency of players in La Liga and the results of matches is explored by using clustering analysis. Selecting indexes include the total number of shots, the number of shots, the total number of goals, and the total number, which are important features to evaluate the quality and efficiency of the players’ shots.
Using K-mean algorithms and hierarchical clustering method to cluster the shooting indicators of players. Through these two algorithms, they are possible to find differences in shooting performance between different groups and explore whether shooting performance between different levels of players is correlated with match results and club rankings. It is super helpful to get a complete understanding of the impact of shooting quality on a club’s results. At the same time, compare the clustering effect produced by K-means and hierarchical clustering algorithm respectively to determine which method is more suitable for this project.
Resource
Example DatasetDataset
Example K-Means Python CodeK-Means Code
Example Hierarchical Clustring R CodeHierarchical Clustring Code

